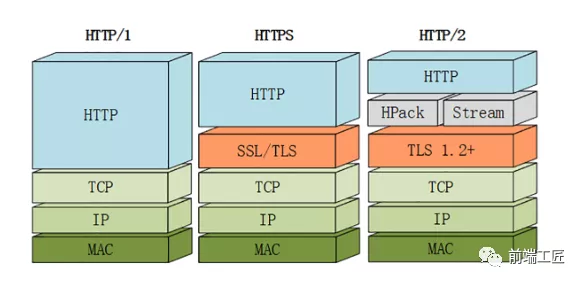
HTTP/1.x的缺陷
1. 连接无法复用
连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对大量小文件请求影响较大(没有达到最大窗口请求就被终止)。
- HTTP/1.0传输数据时,每次都需要重新建立连接,增加延迟。
- HTTP/1.1虽然加入keep-alive可以复用一部分连接,但域名分片等情况下仍然需要建立多个connection,耗费资源,给服务器带来性能压力。
2. 高延迟–队头阻塞(Head-Of-Line Blocking(HOLB))
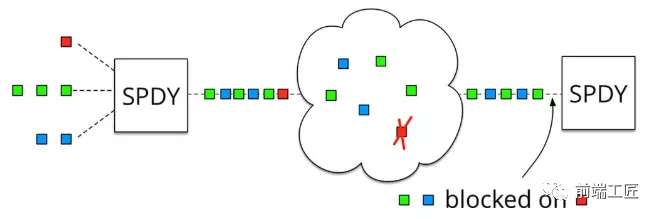
导致带宽无法被充分利用,以及后续健康请求被阻塞。HOLB(http://stackoverflow.com/questions/25221954/spdy-head-of-line-blocking) 是指一系列包(package)因为第一个包被阻塞;当页面中需要请求很多资源的时候,HOLB(队头阻塞)会导致在达到最大请求数量时,剩余的资源需要等待其他资源请求完成后才能发起请求。
- HTTP 1.0:下个请求必须在前一个请求返回后才能发出,request-response对按序发生。显然,如果某个请求长时间没有返回,那么接下来的请求就全部阻塞了。
- HTTP 1.1:尝试使用 pipeling 来解决,即浏览器可以一次性发出多个请求(同个域名,同一条 TCP 链接)。但 pipeling 要求返回是按序的,那么前一个请求如果很耗时(比如处理大图片),那么后面的请求即使服务器已经处理完,仍会等待前面的请求处理完才开始按序返回。所以,pipeling 只部分解决了 HOLB。
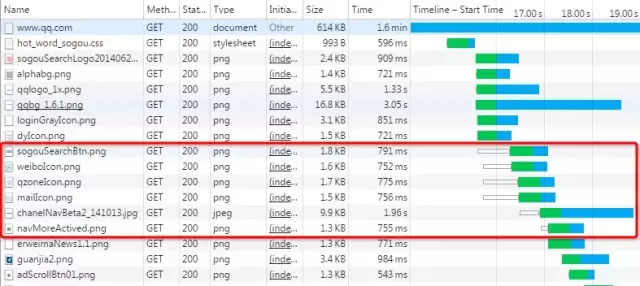
如上图所示,红色圈出来的请求就因域名链接数已超过限制,而被挂起等待了一段时间。
3. 无状态特性–带来的巨大HTTP头部
由于报文Header一般会携带"User Agent"“Cookie”“Accept”"Server"等许多固定的头字段(如下图),多达几百字节甚至上千字节,但Body却经常只有几十字节(比如GET请求、204/301/304响应)。Header里携带的内容过大,在一定程度上增加了传输的成本。更要命的是,成千上万的请求响应报文里有很多字段值都是重复的,非常浪费。
4. 明文传输–带来的不安全性
HTTP/1.1在传输数据时,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性。
5. 不支持服务器推送消息
SPDY 协议
上面我们提到,由于HTTP/1.x的缺陷,我们会引入雪碧图、将小图内联、使用多个域名等等的方式来提高性能。不过这些优化都绕开了协议,直到2009年,谷歌公开了自行研发的 SPDY 协议,主要解决HTTP/1.1效率不高的问题。谷歌推出SPDY,才算是正式改造HTTP协议本身。降低延迟,压缩header等等,SPDY的实践证明了这些优化的效果,也最终带来HTTP/2的诞生。

1. 多路复用 — 解决队头阻塞
SPDY 允许在一个连接上无限制并发流。因为请求在一个通道上,TCP 效率更高(参考 TCP 拥塞控制 中的慢启动)。更少的网络连接,发出更密集的包。
2. 头部压缩 — 解决巨大的 HTTP 头部
使用专门的 HPACK 算法,每次请求和响应只发送差异头部,一般可以达到 50% ~ 90% 的高压缩率。
3. 请求优先级
虽然无限的并发流解决了队头阻塞的问题,但如果带宽受限,客户端可能会因防止堵塞通道而阻止请求。在网络通道被非关键资源堵塞时,高优先级的请求会被优先处理。
4. 服务端推送
服务端推送(Server Push),可以让服务端主动把资源文件推送给客户端。当然客户端也有权利选择是否接收。
5. 提高安全性
支持使用 HTTPS 进行加密传输。
HTTP2
简介
2015年,HTTP/2 发布。HTTP/2是现行HTTP协议(HTTP/1.x)的替代,但它不是重写,HTTP方法/状态码/语义都与HTTP/1.x一样。HTTP/2基于SPDY3,专注于性能,最大的一个目标是在用户和网站间只用一个连接(connection)。SPDY 协议在Chrome浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。
HTTP/2由两个规范(Specification)组成:
- Hypertext Transfer Protocol version 2 - RFC7540
- HPACK - Header Compression for HTTP/2 - RFC7541
特性
1. 二进制传输
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。 HTTP / 1 的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。
接下来我们介绍几个重要的概念:
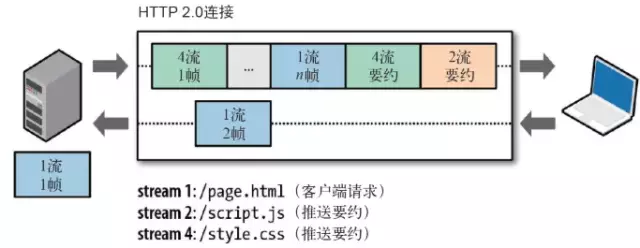
- 流:流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2…N);
- 消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
- 帧:HTTP 2.0 通信的最小单位,每个帧包含帧首部,至少也会标识出当前帧所属的流,承载着特定类型的数据,如 HTTP 首部、负荷,等等
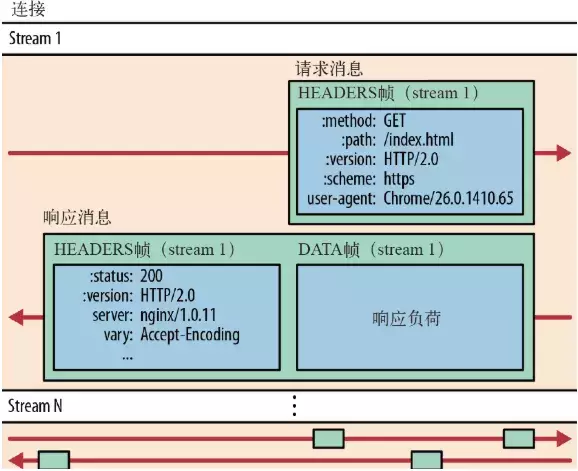
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装
2. 多路复用
在 HTTP/2 中引入了多路复用的技术。多路复用很好的解决了浏览器限制同一个域名下的请求数量的问题,同时也接更容易实现全速传输,毕竟新开一个 TCP 连接都需要慢慢提升传输速度。
大家可以通过该链接(https://http2.akamai.com/demo) 直观感受下 HTTP/2 比 HTTP/1 到底快了多少。

在 HTTP/2 中,有了二进制分帧之后,HTTP /2 不再依赖 TCP 链接去实现多流并行了,在 HTTP/2中:
- 同域名下所有通信都在单个连接上完成。
- 单个连接可以承载任意数量的双向数据流。
- 数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
这一特性,使性能有了极大提升:
- 同个域名只需要占用一个 TCP 连接,使用一个连接并行发送多个请求和响应,消除了因多个 TCP 连接而带来的延时和内存消耗。
- 并行交错地发送多个请求,请求之间互不影响。
- 并行交错地发送多个响应,响应之间互不干扰。
- 在HTTP/2中,每个请求都可以带一个31bit的优先值,0表示最高优先级, 数值越大优先级越低。有了这个优先值,客户端和服务器就可以在处理不同的流时采取不同的策略,以最优的方式发送流、消息和帧。
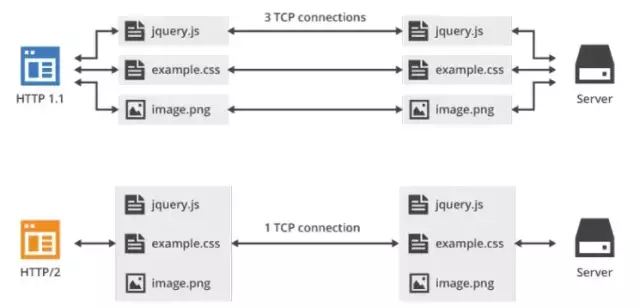
如上图所示,多路复用的技术可以只通过一个 TCP 连接就可以传输所有的请求数据。
3. 头部压缩
在 HTTP/1 中,我们使用文本的形式传输 header,在 header 携带 cookie 的情况下,可能每次都需要重复传输几百到几千的字节。
为了减少这块的资源消耗并提升性能, HTTP/2对这些首部采取了压缩策略:
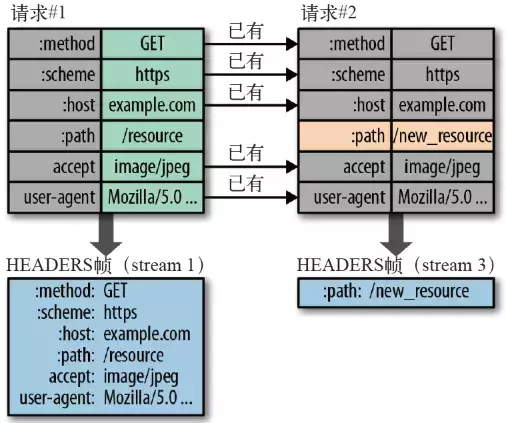
- HTTP/2在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送;
- 首部表在HTTP/2的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
- 每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值
例如下图中的两个请求, 请求一发送了所有的头部字段,第二个请求则只需要发送差异数据,这样可以减少冗余数据,降低开销
4. 服务端推送(Server Push)
Server Push即服务端能通过push的方式将客户端需要的内容预先推送过去,也叫“cache push”。
可以想象以下情况,某些资源客户端是一定会请求的,这时就可以采取服务端 push 的技术,提前给客户端推送必要的资源,这样就可以相对减少一点延迟时间。当然在浏览器兼容的情况下你也可以使用 prefetch。
例如服务端可以主动把JS和CSS文件推送给客户端,而不需要客户端解析HTML时再发送这些请求。
服务端可以主动推送,客户端也有权利选择是否接收。如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送RST_STREAM帧来拒收。主动推送也遵守同源策略,换句话说,服务器不能随便将第三方资源推送给客户端,而必须是经过双方确认才行。
5. 提高安全性
出于兼容的考虑,HTTP/2延续了HTTP/1的“明文”特点,可以像以前一样使用明文传输数据,不强制使用加密通信,不过格式还是二进制,只是不需要解密。
但由于HTTPS已经是大势所趋,而且主流的浏览器Chrome、Firefox等都公开宣布只支持加密的HTTP/2,所以“事实上”的HTTP/2是加密的。也就是说,互联网上通常所能见到的HTTP/2都是使用"https”协议名,跑在TLS上面。HTTP/2协议定义了两个字符串标识符:“h2"表示加密的HTTP/2,“h2c”表示明文的HTTP/2。
HTTP2 的缺陷
TCP以及TCP+TLS建立连接的延时TCP的队头阻塞并没有彻底解决- 多路复用导致服务器压力上升
- 多路复用容易
Timeout
建连延时
TCP连接需要和服务器进行三次握手,即消耗完1.5个 RTT 之后才能进行数据传输。
TLS 连接有两个版本—— TLS 1.2 和 TLS 1.3,每个版本建立连接所花的时间不同,大致需要1~2个 RTT。
RTT(Round-Trip Time): 往返时延。表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。
队头阻塞没有彻底解决
TCP 为了保证可靠传输,有一个“超时重传”机制,丢失的包必须等待重传确认。HTTP2 出现丢包时,整个 TCP 都要等待重传,那么就会阻塞该 TCP 连接中的所有请求。
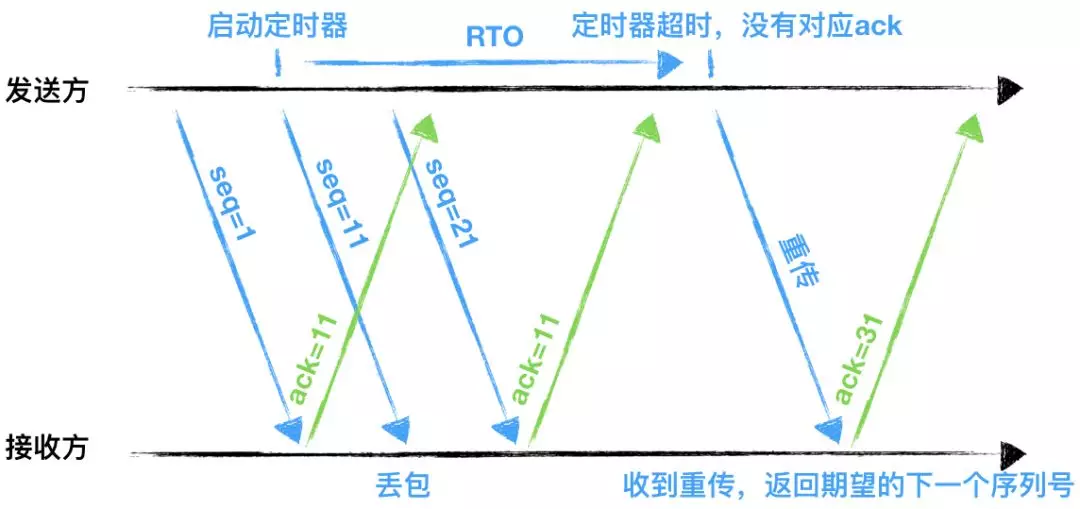
RTO:英文全称是Retransmission TimeOut,即重传超时时间;
RTO是一个动态值,会根据网络的改变而改变。RTO是根据给定连接的往返时间RTT计算出来的。
接收方返回的ack是希望收到的下一组包的序列号。
多路复用导致服务器压力上升
多路复用没有限制同时请求数。请求的平均数量与往常相同,但实际会有许多请求的短暂爆发,导致瞬时 QPS 暴增。
多路复用容易 Timeout
大批量的请求同时发送,由于 HTTP2 连接内存在多个并行的流,而网络带宽和服务器资源有限,每个流的资源会被稀释,虽然它们开始时间相差更短,但却都可能超时。
即使是使用Nginx这样的负载均衡器,想正确进行节流也可能很棘手。
其次,就算你向应用程序引入或调整排队机制,但一次能处理的连接也是有限的。如果对请求进行排队,还要注意在响应超时后丢弃请求,以避免浪费不必要的资源。引用:https://www.lucidchart.com/techblog/2019/04/10/why-turning-on-http2-was-a-mistake/
HTTP3(HTTP-over-QUIC)
上文提到 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致 HTTP/2 的表现情况反倒不如 HTTP/1 了。
因为在出现丢包的情况下,整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。但是对于 HTTP/1.1 来说,可以开启多个 TCP 连接,出现这种情况反到只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。
那么可能就会有人考虑到去修改 TCP 协议,其实这已经是一件不可能完成的任务了。因为 TCP 存在的时间实在太长,已经充斥在各种设备中,并且这个协议是由操作系统实现的,更新起来不大现实。
基于这个原因,Google 就更起炉灶搞了一个基于 UDP 协议的 QUIC 协议,并且使用在了 HTTP/3 上,HTTP/3 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
QUIC 虽然基于 UDP,但是在原本的基础上新增了很多功能,接下来我们重点介绍几个QUIC新功能。
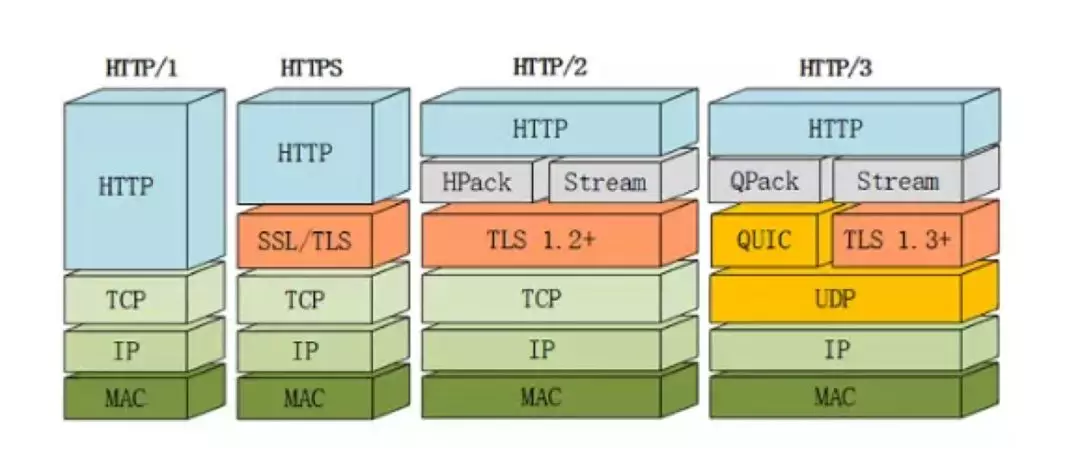
主要特点
- 改进的拥塞控制、可靠传输
- 快速握手
- 集成了 TLS 1.3 加密
- 多路复用
- 连接迁移
1. 改进的拥塞控制、可靠传输
从拥塞算法和可靠传输本身来看,QUIC 只是按照 TCP 协议重新实现了一遍,那么 QUIC 协议到底改进在哪些方面呢?主要有如下几点:
1. 可插拔 — 应用程序层面就能实现不同的拥塞控制算法。
一个应用程序的不同连接也能支持配置不同的拥塞控制。
应用程序不需要停机和升级就能实现拥塞控制的变更,可以针对不同业务,不同网络制式,甚至不同的 RTT,使用不同的拥塞控制算法。
关于应用层的可插拔拥塞控制模拟,可以对 socket 上的流为对象进行实验。
2. 单调递增的 Packet Number — 使用 Packet Number 代替了 TCP 的 seq。
每个 Packet Number 都严格递增,也就是说就算 Packet N 丢失了,重传的 Packet N 的 Packet Number 已经不是 N,而是一个比 N 大的值。而 TCP 重传策略存在二义性,比如客户端发送了一个请求,一个 RTO 后发起重传,而实际上服务器收到了第一次请求,并且响应已经在路上了,当客户端收到响应后,得出的 RTT 将会比真实 RTT 要小。当 Packet N 唯一之后,就可以计算出正确的 RTT。
3. 不允许 Reneging — 一个 Packet 只要被 Ack,就认为它一定被正确接收。
Reneging 的意思是,接收方有权把已经报给发送端 SACK(Selective Acknowledgment) 里的数据给丢了(如接收窗口不够而丢弃乱序的包)。
QUIC 中的 ACK 包含了与 TCP 中 SACK 等价的信息,但 QUIC 不允许任何(包括被确认接受的)数据包被丢弃。这样不仅可以简化发送端与接收端的实现难度,还可以减少发送端的内存压力。
4. 前向纠错(FEC)
QUIC协议有一个非常独特的特性,称为向前纠错 (Forward Error Correction,FEC),每个数据包除了它本身的内容之外,还包括了部分其他数据包的数据,因此少量的丢包可以通过其他包的冗余数据直接组装而无需重传。向前纠错牺牲了每个数据包可以发送数据的上限,但是减少了因为丢包导致的数据重传,因为数据重传将会消耗更多的时间(包括确认数据包丢失、请求重传、等待新数据包等步骤的时间消耗)
假如说这次我要发送三个包,那么协议会算出这三个包的异或值并单独发出一个校验包,也就是总共发出了四个包。当出现其中的非校验包丢包的情况时,可以通过另外三个包计算出丢失的数据包的内容。当然这种技术只能使用在丢失一个包的情况下,如果出现丢失多个包就不能使用纠错机制了,只能使用重传的方式了。
早期的 QUIC 版本存在一个丢包恢复机制,但后来由于增加带宽消耗和效果一般而废弃。FEC 中,QUIC 数据帧的数据混合原始数据和冗余数据,来确保无论到达接收端的 n 次传输内容是什么,接收端都能够恢复所有n个原始数据包。FEC 的实质就是异或。示意图:
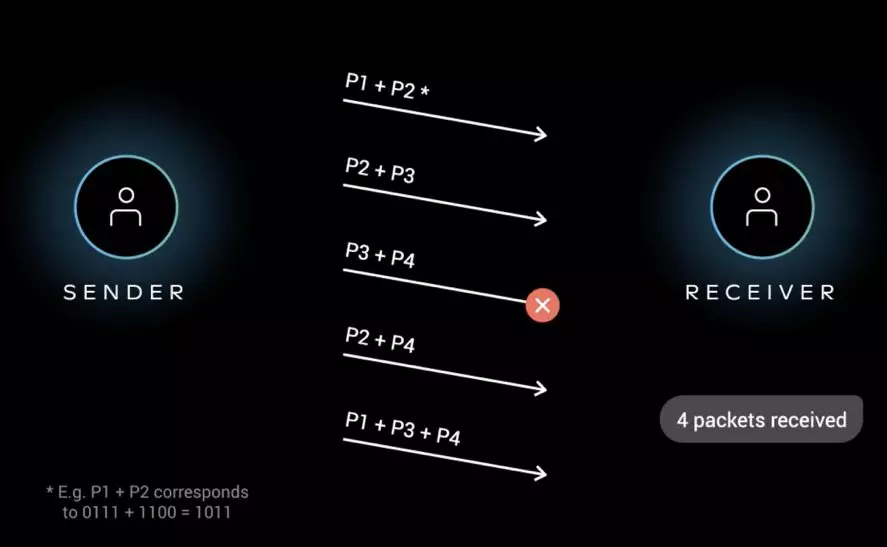
5. 更多的 Ack 块和增加 Ack Delay 时间。
QUIC 可以同时提供 256 个 Ack Block,因此在重排序时,QUIC 相对于 TCP(使用 SACK)更有弹性,这也使得在重排序或丢失出现时,QUIC 可以在网络上保留更多的在途字节。在丢包率比较高的网络下,可以提升网络的恢复速度,减少重传量。
TCP 的 Timestamp 选项存在一个问题:发送方在发送报文时设置发送时间戳,接收方在确认该报文段时把时间戳字段值复制到确认报文时间戳,但是没有计算接收端接收到包到发送 Ack 的时间。这个时间可以简称为 Ack Delay,会导致 RTT 计算误差。现在就是把这个东西加进去计算 RTT 了。
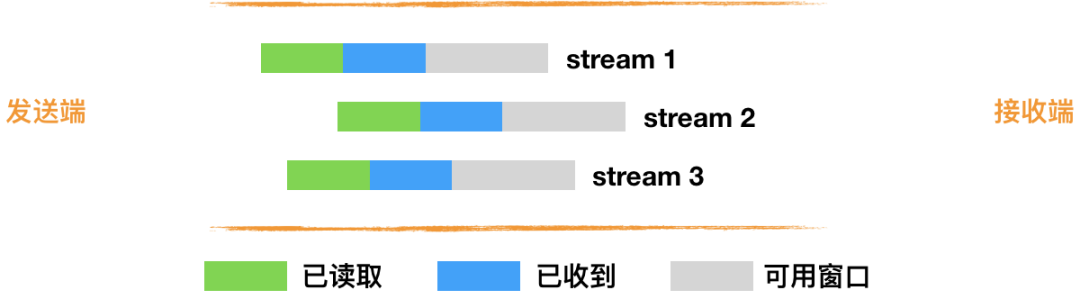
6. 基于 stream 和 connection 级别的流量控制。
为什么需要两类流量控制呢?主要是因为 QUIC 支持多路复用。
Stream 可以认为就是一条 HTTP 请求。
Connection 可以类比一条 TCP 连接。多路复用意味着在一条 Connetion 上会同时存在多条 Stream。
QUIC 接收者会通告每个流中最多想要接收到的数据的绝对字节偏移。随着数据在特定流中的发送,接收和传送,接收者发送 WINDOW_UPDATE 帧,该帧增加该流的通告偏移量限制,允许对端在该流上发送更多的数据。
除了每个流的流控制外,QUIC 还实现连接级的流控制,以限制 QUIC 接收者愿意为连接分配的总缓冲区。连接的流控制工作方式与流的流控制一样,但传送的字节和最大的接收偏移是所有流的总和。
最重要的是,我们可以在内存不足或者上游处理性能出现问题时,通过流量控制来限制传输速率,保障服务可用性。
2. 快速握手
由于 QUIC 是基于 UDP 的,所以 QUIC 可以实现 0-RTT 或者 1-RTT 来建立连接,可以大大提升首次打开页面的速度。
通过使用类似 TCP 快速打开的技术,缓存当前会话的上下文,在下次恢复会话的时候,只需要将之前的缓存传递给服务端验证通过就可以进行传输了。0RTT 建连可以说是 QUIC 相比 HTTP2 最大的性能优势。那什么是 0RTT 建连呢?
这里面有两层含义:
- 传输层 0RTT 就能建立连接。
- 加密层 0RTT 就能建立加密连接。
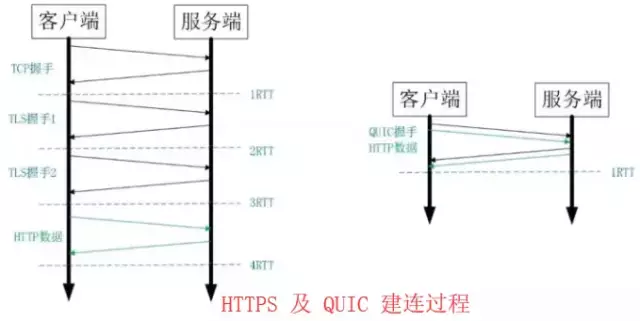
上图左边是 HTTPS 的一次完全握手的建连过程,需要 3 个 RTT。就算是会话复用也需要至少 2 个 RTT。
而 QUIC 呢?由于建立在 UDP 的基础上,同时又实现了 0RTT 的安全握手,所以在大部分情况下,只需要 0 个 RTT 就能实现数据发送,在实现前向加密的基础上,并且 0RTT 的成功率相比 TLS 的会话记录单要高很多
3. 集成了 TLS 1.3 加密
TLS 1.3 支持 3 种基本密钥交换模式:
1 | (EC)DHE (基于有限域或椭圆曲线的 Diffie-Hellman)PSK - onlyPSK with (EC)DHE |
在完全握手情况下,需要 1-RTT 建立连接。 TLS1.3 恢复会话可以直接发送加密后的应用数据,不需要额外的 TLS 握手,也就是 0-RTT。
TLS 1.3 0-RTT 简单原理示意(基于 DHE):
但是 TLS1.3 也并不完美。TLS 1.3 的 0-RTT 无法保证前向安全性(Forward secrecy)。简单讲就是,如果当攻击者通过某种手段获取到了 Session Ticket Key,那么该攻击者可以解密以前的加密数据。
要缓解该问题可以通过设置使得与 Session Ticket Key 相关的 DH 静态参数在短时间内过期(一般几个小时)。
加密认证的报文
TCP 协议头部没有经过任何加密和认证,所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。这些行为有可能是出于性能优化,也有可能是主动攻击。
但是 QUIC 的 packet 可以说是武装到了牙齿。除了个别报文比如 PUBLIC_RESET 和 CHLO,所有报文头部都是经过认证的,报文 Body 都是经过加密的。
这样只要对 QUIC 报文任何修改,接收端都能够及时发现,有效地降低了安全风险。
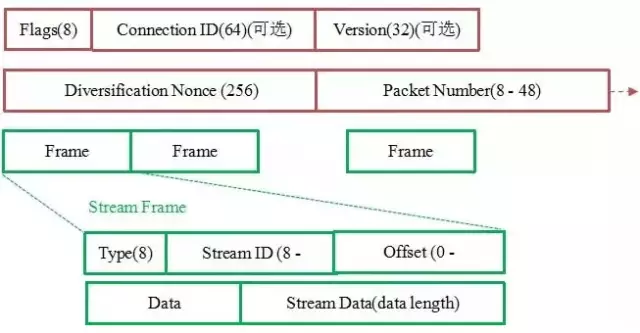
如上图所示,红色部分是 Stream Frame 的报文头部,有认证。绿色部分是报文内容,全部经过加密。
4. 多路复用
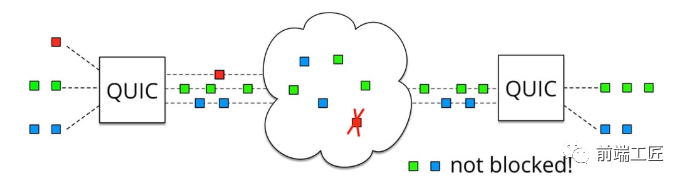
虽然 HTTP/2 支持了多路复用,但是 TCP 协议终究是没有这个功能的。QUIC 原生就实现了这个功能,并且传输的单个数据流可以保证有序交付且不会影响其他的数据流,这样的技术就解决了之前 TCP 存在的问题。
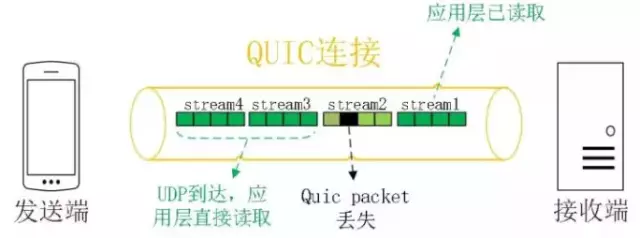
同HTTP2.0一样,同一条 QUIC连接上可以创建多个stream,来发送多个HTTP请求,但是,QUIC是基于UDP的,一个连接上的多个stream之间没有依赖。比如下图中stream2丢了一个UDP包,不会影响后面跟着 Stream3 和 Stream4,不存在 TCP 队头阻塞。虽然stream2的那个包需要重新传,但是stream3、stream4的包无需等待,就可以发给用户。
5. 连接迁移
TCP 是按照 4 要素(客户端IP、端口, 服务器IP、端口) 确定一个连接的。而 QUIC 则是让客户端生成一个 Connection ID (64位)来区别不同连接。只要 Connection ID 不变, 连接就不需要重新建立,即便是客户端的网络发生变化。由于迁移客户端继续使用相同的会话密钥来加密和解密数据包,QUIC 还提供了迁移客户端的自动加密验证。
QUIC 面临的挑战
1. NAT 问题
NAT 概念
为了解决 IP 地址不足的问题,NAT 给一个局域网络只分配一个 IP 地址,这个网络内的主机,则分配私有地址,这些私有地址对外是不可见的,他们对外的通信都要借助那个唯一分配的 IP 地址。所有离开本地网络去往 Internet 的数据报的源 IP 地址需替换为相同的 NAT,区别仅在于端口号不同。
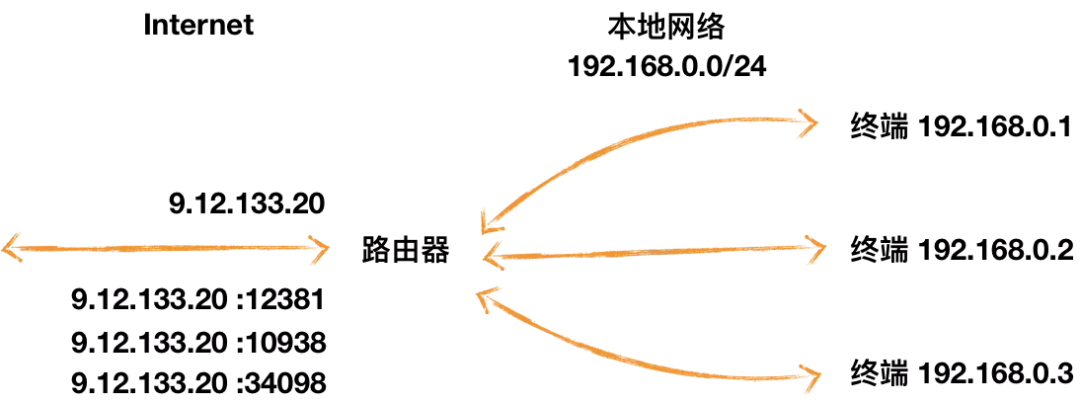
原因
TCP 和 UDP 的报文头部不同导致 NAT 问题的出现。
NAT 设备的端口记忆问题
对于基于 TCP 的 HTTP、HTTPS 传输,NAT 设备可以根据 TCP 报文头的 SYN/FIN 状态位,知道通信什么时候开始,什么时候结束,对应记忆 NAT 映射的开始和结束。
但是基于 UDP 传输的 HTTP3 ,不存在 SYN/FIN 状态位。NAT 设备的记忆如果短于用户会话时间,则用户会话会中断。NAT 设备的记忆时间如果长于用户会话时间,则意味着 NAT 设备的端口资源会被白白占用。
最直接的解决方案是,在 QUIC 的头部模仿 TCP 的 SYN/FIN 状态,让沿途的 NAT 设备知道会话什么时候开始、什么时候结束。但这需要升级全球所有的 NAT 设备的软件。
另外一个可行的方案是,让 QUIC 周期性地发送 Keepalive 消息,刷新 NAT 设备的记忆,避免 NAT 设备自动释放。
NAT设备禁用UDP
在一些 NAT 网络环境下(如某些校园网),UDP 协议会被路由器等中间网络设备禁止,这时客户端会直接降级,选择 HTTPS 等备选通道,保证正常业务请求。
2. NGINX负载均衡问题
概念
QUIC 客户端存在网络制式切换,就算是同一个移动机房,可能第一次业务请求时会落到 A 这台服务器,后续再次连接,就会落到 B 实例上,重复走 1-RTT 的完整握手流程。
全局握手缓存
为所有 QUIC 服务器实例建立一个全局握手缓存。当用户网络发生切换时,下一次的业务请求无论是落到哪一个机房或哪一台实例上,握手建连都会是 0-RTT。
从古至今实时数据传输(音频、视频、游戏等)都面临卡顿、延迟等问题,而
QUIC基于UDP的架构和改进的重传等特性,能够有效的提升用户体验。目前 B站 也已经接入QUIC。如果想要自己体验
QUIC,可以使用libquic、Caddy等。另外GitHub上面也有C++版本 的QUIC实现,利用Nodejs的C++模块,前端工程师也可以快速实现一个node-quic。
历代 HTTP 速度测试
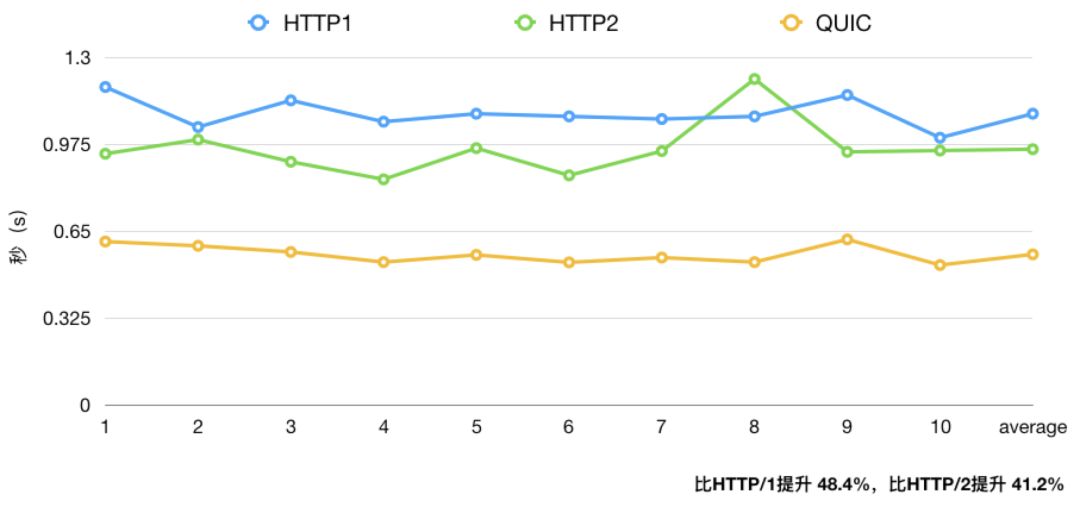
总结
- HTTP/1.1有两个主要的缺点:安全不足和性能不高。
- HTTP/2完全兼容HTTP/1,是“更安全的HTTP、更快的HTTPS",头部压缩、多路复用等技术可以充分利用带宽,降低延迟,从而大幅度提高上网体验;
- QUIC 基于 UDP 实现,是 HTTP/3 中的底层支撑协议,该协议基于 UDP,又取了 TCP 中的精华,实现了即快又可靠的协议。